LuaVela - the LuaJIT fork I've worked on
Recently, IPONWEB open sourced its fork of LuaJIT called LuaVela. The original announcement post can be found here where a lot of details about it can be found.
I’ve worked on LuaVela for the last 7 months and now I want to tell about my experience.
Table Of Contents
Intro
Lua has been dear for me for a long time. It’s an amazing language. It’s easy to integrate it with C++, it’s fast, and it’s a joy to write code with it. I’ve used it in my games and other projects for the last 6 years, so it’s my “mother tongue” as much as C++ at this point.
Another thing that makes Lua dear to me is that the articles I’ve written about it were received very well and this has given me a lot of motivation to write more. If you Google “Lua C++”, you’ll see my blog somewhere on the first page (maybe it’ll even be the first result!). That’s how popular the articles have gotten.
I’ve been fascinated by compilers for a long time, and I’ve always wanted to do some work in that field. And this became possible when I’ve started working at IPONWEB.
LuaJIT’s 2GB problem
You don’t usually stumble upon companies working on their own compilers (or even forks of them). One of the reasons IPONWEB choose to do so, is that it hit (in)famous limitation of LuaJIT: its 2GB RAM limit.
LuaJIT was originally written with 32 bit architecture/pointers in mind. When you ran it on 64 bit platforms, you had a limitation: you could only adress 1GB of RAM (because of mmap limitations), so this was LuaJIT’s memory limit. In newer Linux kernels the limit was raised to 2GB, but it still wasn’t enough for some projects IPONWEB did. This became a serious problem by 2015. LuaJIT 2.1 wasn’t stable enough for production use at this point, and other possible solutions to the problem the problem just weren’t good enough. People at IPONWEB decided to fork LuaJIT.
Forking LuaJIT
Lua community is one of the most segmented communities I’ve ever seen. LuaJIT can be partially blamed for that. A lot of people stayed somewhere between Lua 5.1 and Lua 5.2 because they used LuaJIT. LuaJIT got huge performance gains for them, so migrating to Lua 5.2 and Lua 5.3 was not possible.
LuaJIT also has a lot forks. People add optimizations which work well for them, but don’t work that well in general case. People fix bugs, which can’t be easily ported to upstream, because of its cross-platform support and very high standards to which patches must conform (which are justified!).
When LuaVela (called uJIT internally until the release) became yet another fork, people who started it wanted for it to conform to the standard (vanilla) Lua as much as possible. A lot of tests were added to ensure standard conformance. LuaVela is a “drop-in” replacement for Lua 5.1 and LuaJIT. It’s likely that if you replace your Lua/LuaJIT headers in your code, you’ll just get LuaVela to work with your code and might see performance benifits immediately.
Another thing that was done early on was dropping cross-platform support. We used LuaVela for projects which ran on x86-64 Linux only and it was difficult for our small team to try to support all the other platforms.
What I’ve found interesting about LuaJIT
During my first days at IPONWEB, I’ve started digging into LuaVela’s and LuaJIT’s codebase. There is an in-depth e-mail by Mike Pall (the author of LuaJIT) which explains some of the stuff about how LuaJIT works and why it is so fast and good at generating assembly. I’ll go over a few things I’ve found fascinating about LuaJIT’s implementation.
First of all, LuaJIT’s interpreter is written in assembly (in DynASM, to be precise) and it can perform faster than vanilla Lua 5.1 in 2-4 times. One of the reasons for that are some incredible performance optimizations that were done in handcrafted assembly to reduce the number of RAM lookups and stores. A lot of the computations are done using CPU registers - most of the time you have function’s parameters and local variables stored in CPU registers and so a lot of computations are done without accessing the RAM. There are also some optimizations (like expression folding) which are done at script’s initial convertion to bytecode (when your module is loaded by Lua).
Another cool thing is that LuaJIT and C share the same stack and LuaJIT honors C ABI to do function calls. This is one of the reason why Lua/C calls are so cheap there - they’re almost identical to C function calls.
LuaJIT’s interpreter is written in DynASM, a higher level assembly, which allows you to write “macros”, have constants and other things to make your assembly writing process faster, safer and easier to read. You can find LuaVela’s improved interpreter here. A lot was done to refactor and document original LuaJIT’s interpreter, so I think that it’s a useful learning resource even if you don’t plan to use LuaVela in your project.
When it comes to JIT/compilation part, LuaJIT shines again - it uses a huge number of optimizations to make generated assembly fast. It generates linear “traces” - assembly without branches and jumps. The only jumps that are there are exit conditions: you compile a trace using some invariants and assumptions, e.g. that some variable should stay constant or have a certain type. When this assumption gets broken, you exit the trace, and either find another trace or just continue execution in the interpreter.
All function calls in a trace are inlined - this one also gives a considerable
performance boost. There is also a huge number of “fold” optimizations which
transform things like 2 + 2 + x + x into 4 + 2*x (even function calls,
especially to math functions can be folded sometimes!).
There are also built-ins like string.find or math.abs which are either
written in C/asm, or are written as C functions which tell LuaJIT which IRs to
emit, so you get very efficient assembly as the result of a final trace
generation.
For example, calling math.abs essentially turns into few instructions in a
trace. There’s no table lookup into math table, there’s even no call to C’s
abs function!
LuaJIT’s IR is linear: it’s laid out contiguously in memory. It’s one of the reasons why optimizations and code generation happen quickly and don’t have noticeable performance overhead in most cases.
LuaVela’s new features
What makes LuaVela different from other LuaJIT forks? I’ll quote the original announcement post:
- Full support for 64-bit memory without any tricks or hacks in the interpreter and JIT compiler;
- “Sealing”: An ability to hide some data from the garbage collector. In IPONWEB, we use this generation-like (or, better, Eden-like) trick to mark data with the same lifetime as the application instance itself reducing overall pressure on GC;
- Immutability: Data structures may be (recursively) marked immutable in run-time. This implemented via an extension API, the syntax of the language is unaffected;
- Coroutine timeouts: There are C-level extension APIs that allow to control the life time of coroutines – once a coroutine runs for too long, it is terminated by the virtual machine;
- Some new optimizations in the JIT compiler (but some of them are not brand new if one compares with LuaJIT 2.1);
- New C- and Lua-level extension APIs;
- Platform-level sampling profiler;
- Memory usage profiler;
- Platform-level code coverage.
- CMake is used as a build system for the project;
- 6 test suites are bundled with the project: Lua 5.1 test suite, LuaJIT test suite, CERN MAD test suite (partially), lua-Harness test suite and two suites written inside IPONWEB (for testing at Lua- and C-level, respectively);
- Documentation bundle is included into the release, too. All the docs
are in the RST format and
make docswill build you the HTML version if you have Sphinx installed.
My contributions to LuaVela
Here’s some of the stuff I did in the 7 months that I’ve worked on LuaVela:
- Added
ujit.table.sizebuilt-in for counting non-nil elements in a Lua table (both array and hash parts) - Created
ujit.mathmodule which is used to test if number is finite, +-ifn or NaN (in IEEE-754 terms) - Implemented
ujit.string.trimandujit.string.splitbuilt-ins - the first one removes whitespace from both ends of the string, and another allows you to iterate over strings like this:
local t = {}
for token in ujit.string.split("a,b,c", ",") do
table.insert(t)
end
-- t == { "a", "b", "c" }
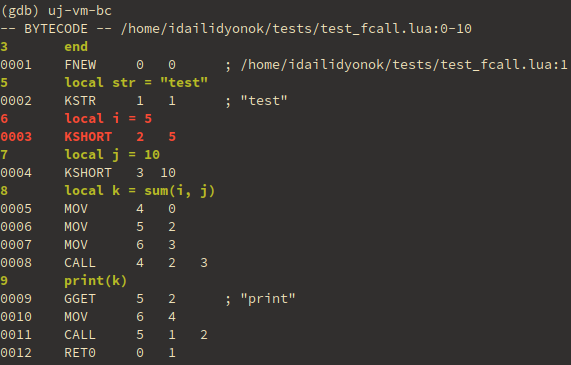
- Improved byte code dumping. LuaJIT and LuaVela have “-b” flag used for
printing byte code of a Lua chunk. I’ve figured out that you can actually do
something close to gdb’s
disas /swith it (when source code lines are printed next to corresponding assembly). The resulting flag “-B” does this:
- Improved testing system and helped make it more consistent across different testing suites.
- Migrated repo from hg to Git. I used hg-fast-export for this, but it wasn’t simple as that. Initially uJIT started inside another repo, and so the history was full of empty commits when the transfer to another repository happened. Also “closing branch” commits from hg were adding a lot of noise. I’ve written a Python script which iterated over the entire history and rewrote it while excluding empty commits and saving authorship, time of commit and feature branches from HG repo.
- Made tons of CMake improvements - the most significant was adding support for
out of source build and testing. Another cool thing was migrating to
ExternalProjectfor third party libraries, which made the build process a lot cleaner. I also introduced some modern CMake practices in our build scripts, which made everyone’s lives a bit easier. - Fixed non-conformant code to enable
-std=c11and-pedantic. LuaJIT used something close to GNU 99 standard for everything, but didn’t really specify the standard. It turned out that GCC is using-std=gnu11by default since GCC 5, so we’ve decided to fix all non-conforming code. Some interesting changes:-std=gnu11allows you to forward declare enums, ISO C doesn’t- You need to explicitly cast pointers to
void*before printing them withprintf, e.g.:
struct some_type* ptr = &some_obj;
printf("pointer: %p", (void*)ptr);
// ^^^^^^^
- Casting a function pointer to
void*is not allowed by C standard, but this is okay to do on Linux, and LuaJIT uses it often for storing callbacks, and dlsym returns void*, so I had to disable -pedantic for lines that do so. ##__VA_ARGS__is not in ISO C, which is painful, because if you have a macro with variadic arguments, you can’t pass “nothing” in such macros- enum values must be initialized with integer constant expressions, but
LuaJIT used
uint32_tforx86Openum - expressions like these are permitted in GNU C, but not in ISO C:
void f() {
return g();
}
- Implemented a process of mirroring patches from internal repo to a public one. We have some internal docs and other secret stuff in the private repo, so I’ve made a script which excludes changes to these files
- I’ve also done a lot of clean up for the code base in general to make sure that when we open source the project, it looks as good as possible.
Future
At the moment, the development of LuaVela is finished. We’ll fix critical bugs, but we felt that LuaVela is close to being feature complete and fast enough for most of our use cases, so we’ve moved on to other projects. LuaVela was open sourced as a “thank you” for Lua and LuaJIT community and developers. I hope that some of the unique things LuaVela has will be later ported to other active forks and make the software which uses it even faster and better.
I’ve enjoyed working on LuaVela: I’ve learned a lot about Lua and JIT compilation. I’ve also got some real life C programming experience. It was great.
Thanks for reading!