How I learned Vulkan and wrote a small game engine with it
tl;dr: I learned some Vulkan and made a game engine with two small game demos in 3 months.
The code for the engine and the games can be found here: https://github.com/eliasdaler/edbr



Table Of Contents
This article documents my experience of learning Vulkan and writing a small game/engine with it. It took me around 3 months to do it without any previous knowledge of Vulkan (I had previous OpenGL experience and some experience with making game engines, though).

The engine wasn’t implemented as a general purpose engine, which is probably why it took me a few months (and not years) to achieve this. I started by making a small 3D game and separated reusable parts into the “engine” afterwards. I can recommend everyone to follow the same process to not get stuck in the weeds (see “Bike-shedding” section below for more advice).
Preface
I’m a professional programmer, but I’m self-taught in graphics programming. I started studying graphics programming around 1.5 years ago by learning OpenGL and writing a 3D engine in it.
The engine I wrote in Vulkan is mostly suited for smaller level-based games. I’ll explain things which worked for me, but they might not be the most efficient. My implementation would probably still be a good starting point for many people.
Hopefully, this article will help make some things about Vulkan clearer to you. But you also need to be patient. It took me months to implement what I have today and I did it by cutting corners in many places. But if a self-taught programmer like me can build something with Vulkan, then so can you!
Learning graphics programming
This is a very high level overview of how I learned some graphics programming myself. If there’s interest, I might write another article with more resources and helpful guidelines.
If you haven’t done any graphics programming before, you should start with OpenGL. It’s much easier to learn it and not get overwhelmed by all the complexity that Vulkan has. A lot of your OpenGL and graphics programming knowledge will be useful when you start doing things with Vulkan later.
Ideally, you should at least get a textured model displayed on the screen with some simple Blinn-Phong lighting. I can also recommend doing some basic shadow mapping too, so that you learn how to render your scene from a different viewpoint and to a different render target, how to sample from depth textures and so on.
I can recommend using the following resources to learn OpenGL:
- https://learnopengl.com/
- Anton’s OpenGL 4 Tutorials book
- Thorsten Thormählen’s lectures lectures (watch the first 6 videos, the rest might be a bit too advanced)
Sadly, most OpenGL resources don’t teach the latest OpenGL 4.6 practices. They make writing OpenGL a lot more enjoyable. If you learn them, transitioning to Vulkan will be much easier (I only learned about OpenGL 3.3 during my previous engine development, though, so it’s not a necessity).
Here are some resources which teach you the latest OpenGL practices:
- https://juandiegomontoya.github.io/modern_opengl.html
- https://github.com/fendevel/Guide-to-Modern-OpenGL-Functions
It’s also good to have some math knowledge, especially linear algebra: how to work with vectors, transformation matrices and quaternions. My favorite book about linear algebra/math is 3D Math Primer for Graphics and Game Development by F. Dunn and I. Parbery. You don’t need to read it all in one go - use it as a reference if some math in the OpenGL resources above doesn’t make sense to you.
Bike-shedding and how to avoid it
https://en.wikipedia.org/wiki/Law_of_triviality
Ah, bike-shedding… Basically, it’s a harmful pattern of overthinking and over-engineering even the simplest things. It’s easy to fall into this trap when doing graphics programming (especially when doing Vulkan since you need to make many choices when implementing an engine with it).
- Always ask yourself “Do I really need this?”, “Will this thing ever become a bottleneck?”.
- Remember that you can always rewrite any part of your game/engine later.
- Don’t implement something unless you need it right now. Don’t think “Well, a good engine needs X, right…?”.
- Don’t try to make a general purpose game engine. It’s probably even better to not think about “the engine” at first and write a simple game.
- Make a small game first - a Breakout clone, for example. Starting your engine development by doing a Minecraft clone with multiplayer support is probably not a good idea.
- Be wary of people who tend to suggest complicated solutions to simple problems.
- Don’t look too much at what other people do. I’ve seen many over-engineered engines on GitHub - sometimes they’re that complex for a good reason (and there are years of work behind them). But you probably don’t need most of that complexity, especially for simpler games.
- Don’t try to make magical wrappers around Vulkan interfaces prematurely, especially while you’re still learning Vulkan.
Get it working first. Leave “TODO”/“FIXME” comments in some places. Then move on to the next thing. Try to fix “TODO”/“FIXME” places only when they really become problematic or bottleneck your performance. You’ll be surprised to see how many things won’t become a problem at all.
Some of this advice only applies when you’re working alone on a hobby project. Of course, it’s much harder to rewrite something from scratch when others start to depend on it and a “temp hack” becomes a fundamental part of the engine which is very hard to change without breaking many things.
Why Vulkan?
Ask yourself if you need to learn a graphics API at all. If your main goal is to make a game as soon as possible, then you might be better off using something like Godot or Unreal Engine.
However, there’s nothing wrong with reinventing the wheel or doing something from scratch. Especially if you do it just for fun, to get into graphics programming or to get an in-depth knowledge about how something works.
The situation with graphic APIs in 2024 is somewhat complicated. It all depends on the use case: DirectX seems like the most solid choice for most AAA games. WebGL or WebGPU are the only two choices for doing 3D graphics on the web. Metal is the go-to graphics API on macOS and iOS (though you can still do Vulkan there via MoltenVK).
My use case is simple: I want to make small 3D games for desktop platforms (Windows and Linux mostly). I also love open source technology and open standards. So, it was a choice between OpenGL and Vulkan for me.
OpenGL is a good enough choice for many small games. But it’s very unlikely that it’ll get new versions in the future (so you can’t use some newest GPU capabilities like ray tracing), it’s deprecated on macOS and its future is uncertain.
WebGPU was also a possible choice. Before learning Vulkan, I learned some of it. It’s a pretty solid API, but I had some problems with it:
- It’s still not stable and there’s not a lot of tutorials and examples for it. This tutorial is fantastic, though.
- WGSL is an okay shading language, but I just find its syntax not as pleasant as GLSL’s (note that you can write in GLSL and then load compiled SPIR-V on WebGPU native).
- On desktop, it’s essentially a wrapper around other graphic APIs (DirectX, Vulkan, Metal).This introduces additional problems for me:
- It can’t do things some things that Vulkan or DirectX can do.
- It has more limitations than native graphic APIs since it needs to behave similarly between them.
- RenderDoc captures become confusing as they differ between the platforms (you can get DirectX capture on Windows and Vulkan capture on Linux) and you don’t have 1-to-1 mapping between WebGPU calls and native API calls.
- Using Dawn and WGPU feels like using bgfx or sokol. You don’t get the same degree of control over the GPU and some of the choices/abstractions might not be the most pleasant for you.
- No bindless textures (WIP discussion here).
- No push constants (WIP discussion here).
Still, I think that WebGPU is a better API than OpenGL/WebGL and can be more useful to you than Vulkan in some use cases:
- Validation errors are much better than in OpenGL/WebGL and not having global state helps a lot.
- It’s also kind of similar to Vulkan in many things, so learning a bit of it before diving into Vulkan also helped me a lot.
- It requires a lot less boilerplate to get things on the screen (compared to Vulkan).
- You don’t have to deal with explicit synchronization which makes things much simpler.
- You can make your games playable inside the browser.
Learning Vulkan
Learning Vulkan seemed like an impossible thing for me previously. It felt like you needed to have many years of AAA game graphics programming experience to be able to do things in it. You also hear people saying “you’re basically writing a graphics driver when writing in Vulkan” which also made Vulkan sounds like an incredibly complicated thing.
I have also checked out some engines written in Vulkan before and was further demotivated by seeing tons of scary abstractions and files named like GPUDevice.cpp or GPUAbstraction.cpp which had thousands of lines of scary C++ code.
The situation has changed over the years. Vulkan is not as complicated as it was before. First of all, Khronos realized that some parts of Vulkan were indeed very complex and introduced some newer features which made many things much simpler (for example, dynamic rendering). Secondly, some very useful libraries which reduce boilerplate were implemented. And finally, there are a lot of fantastic resources which make learning Vulkan much easier than it was before.
The best Vulkan learning resource which helped me get started was vkguide. If you’re starting from scratch, just go through it all (you might stop at “GPU driver rendering” chapter at first - many simple games probably won’t need this level of complexity)
Vulkan Lecture Series by TU Wien also nicely teaches Vulkan basics (you can probably skip “Real-Time Ray Tracing” chapter for now). I especially found a lecture on synchronization very helpful.
Here are some more advanced Vulkan books that also helped me:
- 3D Graphics Rendering Cookbook by Sergey Kosarevsky and Viktor Latypov. There is the second edition in the writing and it’s promising to be better than the first one. The second edition is not released yet, but the source code for it can be found here: https://github.com/PacktPublishing/3D-Graphics-Rendering-Cookbook-Second-Edition
- Mastering Graphics Programming with Vulkan by Marco Castorina, Gabriel Sassone. Very advanced book which explains some of the “cutting edge” graphics programming concepts (I mostly read it to understand where to go further, but didn’t have time to implement most of it). The source code for it can be found here: https://github.com/PacktPublishing/Mastering-Graphics-Programming-with-Vulkan
Here’s the result of my first month of learning Vulkan:

By this point I had:
- glTF model loading
- Compute skinning
- Frustum culling
- Shadow mapping and cascaded shadow maps
Of course, doing it for the 3rd time (I had it implemented it all in OpenGL and WebGPU before) certainly helped. Once you get to this point, Vulkan won’t seem as scary anymore.
Let’s see how the engine works and some useful things I learned.
Engine overview and frame analysis
https://github.com/eliasdaler/edbr
My engine is called EDBR (Elias Daler’s Bikeshed Engine) and was initially started as a project for learning Vulkan. It quickly grew into a somewhat usable engine which I’m going to use for my further projects.
At the time of writing this article, the source code line counts are as follows:
- Engine itself: 19k lines of code
- 6.7k LoC related to graphics,
- 2k LoC are light abstractions around Vulkan
- 3D cat game: 4.6k LoC
- 2D platformer game: 1.2k LoC
I copy-pasted some non-graphics related stuff from my previous engine (e.g. input handling and audio system) but all of the graphics and many other core systems were rewritten from scratch. I feel like it was a good way to do it instead of trying to cram Vulkan into my old OpenGL abstractions.
You can follow the commit history which shows how I started from clearing the screen, drawing the first triangle, drawing a textured quad and so on. It might be easier to understand the engine when it was simpler and smaller.
Let’s see how this frame in rendered:
Most of the steps will be explained in more detail below.
- Skinning
First, models with skeletal animations are skinned in the compute shader. The compute shader takes unskinned mesh and produces a buffer of vertices which are then used instead of the original mesh in later rendering steps. This allows me to treat static and skinned meshes similarly in shaders and not do skinning repeatedly in different rendering steps.
- CSM (Cascaded Shadow Mapping)
I use a 4096x4096 depth texture with 3 slices for cascaded shadow mapping. The first slice looks like this:

- Geometry + shading
All the models are drawn and shading is calculated using the shadow map and light info. I use a PBR model which is almost identical to the one described in Physically Based Rendering in Filament. The fragment shader is quite big and does calculation for all the lights affecting the drawn mesh in one draw call:

Everything is drawn into a multi-sampled texture. Here’s how it looks after resolve:

(Open the previous two screenshots in the next tab and flip between the tabs to see the difference more clearly)
- Depth resolve
Depth resolve step is performed manually via a fragment shader. I just go through all the fragments of multi-sample depth texture and write the minimum value into the non-MS depth texture (it’ll be useful in the next step).
- Post FX

Some post FX is applied - right now it’s only depth fog (I use “depth resolve” texture from the previous step here), afterwards tone-mapping and bloom will also be done here.
- UI
Dialogue UI is drawn. Everything is done in one draw call (more is explained in “Drawing many sprites” section)
And that’s it! It’s pretty basic right now and would probably become much more complex in the future (see “Future work” section).
General advice
Recommended Vulkan libraries
There are a couple of libraries which greatly improve the experience of writing Vulkan. Most of them are already used in vkguide, but I still want to highlight how helpful they were to me.
- vk-bootstrap - https://github.com/charles-lunarg/vk-bootstrap
vk-bootstrap simplifies a lot of Vulkan boilerplate: physical device selection, swapchain creation and so on.
I don’t like big wrappers around graphic APIs because they tend to be very opinionated. Plus, you need to keep a mental map of “wrapper function vs function in the API spec” in your head at all times.
Thankfully, vk-bootstrap is not like this. It mostly affects the initialization step of your program and doesn’t attempt to be a wrapper around every Vulkan function.
When I was learning Vulkan, I started doing Vulkan from scratch, without using any 3rd party libraries. Replacing big amounts of the initialization code with vk-bootstrap was a joy. It’s really worth it.
- Vulkan Memory Allocator (VMA) - https://github.com/GPUOpen-LibrariesAndSDKs/VulkanMemoryAllocator
I’ll be honest, I used VMA without even learning about how to allocate memory in Vulkan manually. I read about it in the Vulkan spec later - I’m glad that I didn’t have to do it on my own.
- volk
Volk was very useful for me for simplifying extension function loading. For example, if you want to use very useful vkSetDebugUtilsObjectNameEXT for setting debug names for your objects (useful for RenderDoc captures and validation errors), you’ll need to do this if you don’t use volk:
// store this pointer somewhere
PFN_vkSetDebugUtilsObjectNameEXT pfnSetDebugUtilsObjectNameEXT;
// during your game init
pfnSetDebugUtilsObjectNameEXT = (PFN_vkSetDebugUtilsObjectNameEXT)
vkGetInstanceProcAddr(instance, "vkSetDebugUtilsObjectNameEXT");
// and finally in your game code
pfnSetDebugUtilsObjectNameEXT(device, ...);
With volk, all the extensions are immediately loaded after you call volkInitialize and you don’t need to store these pointers everywhere. You just include volk.h and call vkSetDebugUtilsObjectNameEXT - beautiful!
GfxDevice abstraction
I have a GfxDevice class which encapsulates most of the commonly used functionality and stores many objects that you need for calling Vulkan functions (VkDevice, VkQueue and so on). A single GfxDevice instance is created on the startup and then gets passed around.
It handles:
- Vulkan context initialization.
- Swapchain creation and management.
beginFramereturns a newVkCommandBufferwhich is later used in all the drawing steps.endFramedoes drawing to the swapchain and does sync between the frames.- Image creation and loading textures from files.
- Buffer creation.
- Bindless descriptor set management (see “Bindless descriptors” section below).
That’s… a lot of things. However, it’s not that big: GfxDevice.cpp is only 714 lines at the time of writing this article. It’s more convenient to pass one object into the function instead of many (VkDevice, VkQueue, VmaAllocator and so on).
Handling shaders
In Vulkan, you can use any shading language which compiles to SPIR-V - that means that you can use GLSL, HLSL and others. I chose GLSL because I already knew it from my OpenGL experience.
You can pre-compile your shaders during the build step or compile them on the fly. I do it during the build so that my shader loading runtime code is simpler. I also don’t have an additional runtime dependency on the shader compiler. Also, shader errors are detected during the build step and I don’t get compile errors during the runtime.
I use glslc (from shaderc project, it’s included in Vulkan SDK) which allows you to specify a DEPFILE in CMake which is incredibly useful when you use shader includes. If you change a shader file, all files which include it are recompiled automatically. Without the DEPFILE, CMake won’t be able to see which files shader files need to be recompiled and will only recompile the file which was changed.
My CMake script for building shaders looks like this:
function (target_shaders target shaders)
set(SHADERS_BUILD_DIR "${CMAKE_CURRENT_BINARY_DIR}/shaders")
file(MAKE_DIRECTORY "${SHADERS_BUILD_DIR}")
foreach (SHADER_PATH ${SHADERS})
get_filename_component(SHADER_FILENAME "${SHADER_PATH}" NAME)
set(SHADER_SPIRV_PATH "${SHADERS_BUILD_DIR}/${SHADER_FILENAME}.spv")
set(DEPFILE "${SHADER_SPIRV_PATH}.d")
add_custom_command(
COMMENT "Building ${SHADER_FILENAME}"
OUTPUT "${SHADER_SPIRV_PATH}"
COMMAND ${GLSLC} "${SHADER_PATH}" -o "${SHADER_SPIRV_PATH}" -MD -MF ${DEPFILE} -g
DEPENDS "${SHADER_PATH}"
DEPFILE "${DEPFILE}"
)
list(APPEND SPIRV_BINARY_FILES ${SHADER_SPIRV_PATH})
endforeach()
set(shaders_target_name "${target}_build_shaders")
add_custom_target(${shaders_target_name}
DEPENDS ${SPIRV_BINARY_FILES}
)
add_dependencies(${target} ${shaders_target_name})
endfunction()
and then in the main CMakeLists file:
set(SHADERS
skybox.frag
skinning.comp
... // etc
)
# prepend shaders directory path
get_target_property(EDBR_SOURCE_DIR edbr SOURCE_DIR)
set(EDBR_SHADERS_DIR "${EDBR_SOURCE_DIR}/src/shaders/")
list(TRANSFORM SHADERS PREPEND "${EDBR_SHADERS_DIR}")
target_shaders(game ${SHADERS})
Now, when you build a game target, shaders get built automatically and the resulting SPIR-V files are put into the binary directory.
Push constants, descriptor sets and bindless descriptors
Passing data to shaders in OpenGL is much simpler than it is in Vulkan. In OpenGL, you could just do this:
In shader:
uniform float someFloat;
In C++ code:
const auto loc = glGetUniformLocation(shader, "someFloat");
glUseProgram(shader);
glUniform1f(loc, 42.f);
You can also use explicit uniform location like this.
In shader:
layout(location = 20) uniform float someFloat;
In code:
const auto loc = 20;
glUniform1f(loc, 42.f);
In Vulkan, you need to group your uniforms into “descriptor sets”:
// set 0
layout (set = 0, binding = 0) uniform float someFloat;
layout (set = 0, binding = 1) uniform mat4 someMatrix;
// set 1
layout (set = 1, binding = 0) uniform float someOtherFloat;
... // etc.
Now, this makes things a lot more complicated, because you need to specify descriptor set layout beforehand, use descriptor set pools and allocate descriptor sets with them, do the whole VkWriteDescriptorSet + vkUpdateDescriptorSets thing, call vkCmdBindDescriptorSets for each descriptor set and so on.
I’ll explain later how I avoided using descriptor sets by using bindless descriptors and buffer device access. Basically, I only have one “global” descriptor set for bindless textures and samplers, and that’s it. Everything else is passed via push constants which makes everything much easier to handle.
Pipeline pattern
I separate drawing steps into “pipeline” classes.
Most of them look like this:
class PostFXPipeline {
public:
void init(GfxDevice& gfxDevice, VkFormat drawImageFormat);
void cleanup(VkDevice device);
void draw(
VkCommandBuffer cmd,
GfxDevice& gfxDevice,
const GPUImage& drawImage,
const GPUImage& depthImage,
const GPUBuffer& sceneDataBuffer);
private:
VkPipelineLayout pipelineLayout;
VkPipeline pipeline;
struct PushConstants {
VkDeviceAddress sceneDataBuffer;
std::uint32_t drawImageId;
std::uint32_t depthImageId;
};
};
initloads needed shaders and initializespipelineandpipelineLayout:
void PostFXPipeline::init(GfxDevice& gfxDevice, VkFormat drawImageFormat)
{
const auto& device = gfxDevice.getDevice();
const auto pcRange = VkPushConstantRange{
.stageFlags = VK_SHADER_STAGE_FRAGMENT_BIT,
.offset = 0,
.size = sizeof(PushConstants),
};
const auto layouts = std::array{gfxDevice.getBindlessDescSetLayout()};
const auto pushConstantRanges = std::array{pcRange};
pipelineLayout = vkutil::createPipelineLayout(device, layouts, pushConstantRanges);
const auto vertexShader =
vkutil::loadShaderModule("shaders/fullscreen_triangle.vert.spv", device);
const auto fragShader =
vkutil::loadShaderModule("shaders/postfx.frag.spv", device);
pipeline = PipelineBuilder{pipelineLayout}
.setShaders(vertexShader, fragShader)
.setInputTopology(VK_PRIMITIVE_TOPOLOGY_TRIANGLE_LIST)
.setPolygonMode(VK_POLYGON_MODE_FILL)
.disableCulling()
.setMultisamplingNone()
.disableBlending()
.setColorAttachmentFormat(drawImageFormat)
.disableDepthTest()
.build(device);
vkutil::addDebugLabel(device, pipeline, "postFX pipeline");
vkDestroyShaderModule(device, vertexShader, nullptr);
vkDestroyShaderModule(device, fragShader, nullptr);
}
The init function is usually called once during the engine initialization. PipelineBuilder abstraction is described in vkguide here. I modified it a bit to use the Builder pattern to be able to chain the calls.
cleanupdoes all the needed cleanup. It usually simply destroys the pipeline and its layout:
void PostFXPipeline::cleanup(VkDevice device)
{
vkDestroyPipeline(device, pipeline, nullptr);
vkDestroyPipelineLayout(device, pipelineLayout, nullptr);
}
drawis called each frame and all the needed inputs are passed as arguments. It’s assumed that the sync is performed outside of thedrawcall (see “Synchronization” section below). Some pipelines are only called once per frame - some either takestd::vectorof objects to draw or are called like this:
for (const auto& mesh : meshes) {
somePipeline.draw(cmd, gfxDevice, mesh, ...);
}
The typical draw function looks like this:
void PostFXPipeline::draw(
VkCommandBuffer cmd,
GfxDevice& gfxDevice,
const GPUImage& drawImage,
const GPUImage& depthImage,
const GPUBuffer& sceneDataBuffer)
{
// Bind the pipeline
vkCmdBindPipeline(cmd, VK_PIPELINE_BIND_POINT_GRAPHICS, pipeline);
// Bind the bindless descriptor set
gfxDevice.bindBindlessDescSet(cmd, pipelineLayout);
// Handle push constants
const auto pcs = PushConstants{
// BDA - explained below
.sceneDataBuffer = sceneDataBuffer.address,
// bindless texture ids - no need for desc. sets!
// explained below
.drawImageId = drawImage.getBindlessId(),
.depthImageId = depthImage.getBindlessId(),
};
vkCmdPushConstants(
cmd, pipelineLayout, VK_SHADER_STAGE_FRAGMENT_BIT, 0, sizeof(PushConstants), &pcs);
// Finally, do some drawing. Here we're drawing a fullscreen triangle
// to do a full-screen effect.
vkCmdDraw(cmd, 3, 1, 0, 0);
}
Note another thing: it’s assumed that draw is called between vkCmdBeginRendering and vkCmdEndRendering - the render pass itself doesn’t care what texture it renders to - the caller of draw is responsible for that. It makes things simpler and allows you to do several draws to the same render target, e.g.:
// handy wrapper for creating VkRenderingInfo
const auto renderInfo = vkutil::createRenderingInfo({
.renderExtent = drawImage.getExtent2D(),
.colorImageView = drawImage.imageView,
.colorImageClearValue = glm::vec4{0.f, 0.f, 0.f, 1.f},
.depthImageView = depthImage.imageView,
.depthImageClearValue = 0.f,
// for MSAA
.resolveImageView = resolveImage.imageView,
});
vkCmdBeginRendering(cmd, &renderInfo.renderingInfo);
// draw meshes
for (const auto& mesh : meshesToDraw) {
meshPipeline.draw(cmd, gfxDevice, mesh, ...);
}
// draw sky
skyboxPipeline.draw(cmd, gfxDevice, camera);
vkCmdEndRendering(cmd);
I useVK_KHR_dynamic_renderingeverywhere. I don’t use Vulkan render passes and subpasses at all. I’ve heard that they’re more efficient on tile-based GPUs, but I don’t care about mobile support for now.VK_KHR_dynamic_renderingjust makes everything much easier.
Using programmable vertex pulling (PVP) + buffer device address (BDA)
I have one vertex type for all the meshes. It looks like this:
struct Vertex {
vec3 position;
float uv_x;
vec3 normal;
float uv_y;
vec4 tangent;
};
Of course, you can greatly optimize it using various methods, but it’s good enough for me for now. Theuv_x/uv_yseparation comes from vkguide - I think it’s a nice idea to get good alignment and not waste any bytes
The vertices are accessed in the shader like this:
layout (buffer_reference, std430) readonly buffer VertexBuffer {
Vertex vertices[];
};
layout (push_constant, scalar) uniform constants
{
VertexBuffer vertexBuffer;
... // other stuff
} pcs;
void main()
{
Vertex v = pcs.vertexBuffer.vertices[gl_VertexIndex];
...
}
PVP frees you from having to define vertex format (no more VAOs like in OpenGL or VkVertexInputBindingDescription + VkVertexInputAttributeDescription in Vulkan). BDA also frees you from having to bind a buffer to a descriptor set - you just pass an address to your buffer which contains vertices in push constants and that’s it.
Also note the scalar layout for push constants. I use it for all the buffers too. Compared to “std430” layout, it makes alignment a lot more easy to handle - it almost works the same as in C++ and greatly reduces the need for “padding” members in C++ structs.
Bindless descriptors
Textures were painful to work with even in OpenGL - you had “texture slots” which were awkward to work with. You couldn’t just sample any texture from the shader if it wasn’t bound to a texture slot beforehand. ARB_bindless_texture changed that and made many things easier.
Vulkan doesn’t have the exact same functionality, but it has something similar. You can create big descriptor sets which look like this:
// bindless.glsl
layout (set = 0, binding = 0) uniform texture2D textures[];
...
layout (set = 0, binding = 1) uniform sampler samplers[];
You’ll need to maintain a list of all your textures using some “image manager” and when a new texture is loaded, you need to insert it into the textures array. The index at which you inserted it becomes a bindless “texture id” which then can be used to sample it in shaders. Now you can pass these ids in your push constants like this:
layout (push_constant, scalar) uniform constants
{
uint textureId;
...
} pcs;
and then you can sample your texture in the fragment shader like this:
// bindless.glsl
#define NEAREST_SAMPLER_ID 0
...
vec4 sampleTexture2DNearest(uint texID, vec2 uv) {
return texture(nonuniformEXT(sampler2D(textures[texID], samplers[NEAREST_SAMPLER_ID])), uv);
}
// shader.frag
vec4 color = sampleTexture2DNearest(pcs.textureId, inUV);
Two things to note:
- I chose separate image samplers so that I could sample any texture using different samplers. Common samplers (nearest, linear with anisotropy, depth texture samplers) are created and put into
samplersarray on the startup. - The wrapper function makes the process of sampling a lot more convenient.
The placement of nonuniformEXT is somewhat tricky and is explained very well here.
I use bindless ids for the mesh material buffer which looks like this:
struct MaterialData {
vec4 baseColor;
vec4 metallicRoughnessEmissive;
uint diffuseTex;
uint normalTex;
uint metallicRoughnessTex;
uint emissiveTex;
};
layout (buffer_reference, std430) readonly buffer MaterialsBuffer {
MaterialData data[];
} materialsBuffer;
Now I can only pass material ID in my push constants and then sample texture like this in the fragment shader:
MaterialData material = materials[pcs.materialID];
vec4 diffuse = sampleTexture2DLinear(material.diffuseTex, inUV);
...
Neat! No more bulky descriptor sets, just one int per material in the push constants.
You can also put different texture types into the same set like this (this is needed for being able to access textures of types other than texture2D):
layout (set = 0, binding = 0) uniform texture2D textures[];
layout (set = 0, binding = 0) uniform texture2DMS texturesMS[];
layout (set = 0, binding = 0) uniform textureCube textureCubes[];
layout (set = 0, binding = 0) uniform texture2DArray textureArrays[];
And here’s how you can sample textureCube with a linear sampler (note that we use textureCubes here instead of textures):
vec4 sampleTextureCubeLinear(uint texID, vec3 p) {
return texture(nonuniformEXT(samplerCube(textureCubes[texID], samplers[NEAREST_SAMPLER_ID])), p);
}
Here’s a very good article on using bindless textures in Vulkan:
https://jorenjoestar.github.io/post/vulkan_bindless_texture/
Handling dynamic data which needs to be uploaded every frame
I find it useful to pre-allocate big arrays of things and push stuff to them in every frame.
Basically, you can pre-allocate an array of N structs (or matrices) and then start at index 0 at each new frame and push things to it from the CPU. Then, you can access all these items in your shaders. For example, I have all joint matrices stored in one big mat4 array and the skinning compute shader accesses joint matrices of a particular mesh using start index passed via push constants (more about it will be explained later).
Here are two ways of doing this:
-
- Have N buffers on GPU and swap between them.
vkguide explains the concept of “in flight” frames pretty well. To handle this parallelism properly, you need to have one buffer for the “currently drawing” frame and one buffer for “currently recording new drawing commands” frame to not have races. (If you have more frames in flight, you’ll need to allocate more than 2 buffers)
This means that you need to preallocate 2 buffers on GPU. You write data from CPU to GPU to the first buffer during the first frame. While you record the second frame, GPU reads from the first buffer while you write new data to the second buffer. On the third frame, GPU reads from the second buffer and you write new info to the first buffer… and so on.
-
- One buffer on GPU and N “staging” buffers on CPU
This might be useful if you need to conserve some memory on the GPU.
Let’s see how it works in my engine:
class NBuffer {
public:
void init(
GfxDevice& gfxDevice,
VkBufferUsageFlags usage,
std::size_t dataSize,
std::size_t numFramesInFlight,
const char* label);
void cleanup(GfxDevice& gfxDevice);
void uploadNewData(
VkCommandBuffer cmd,
std::size_t frameIndex,
void* newData,
std::size_t dataSize,
std::size_t offset = 0);
const GPUBuffer& getBuffer() const { return gpuBuffer; }
private:
std::size_t framesInFlight{0};
std::size_t gpuBufferSize{0};
std::vector<GPUBuffer> stagingBuffers;
GPUBuffer gpuBuffer;
bool initialized{false};
};
void NBuffer::init(
GfxDevice& gfxDevice,
VkBufferUsageFlags usage,
std::size_t dataSize,
std::size_t numFramesInFlight,
const char* label)
{
...
gpuBuffer = gfxDevice.createBuffer(
dataSize, usage | VK_IMAGE_USAGE_TRANSFER_DST_BIT, VMA_MEMORY_USAGE_AUTO_PREFER_DEVICE);
vkutil::addDebugLabel(gfxDevice.getDevice(), gpuBuffer.buffer, label);
for (std::size_t i = 0; i < numFramesInFlight; ++i) {
stagingBuffers.push_back(gfxDevice.createBuffer(
dataSize, usage | VK_BUFFER_USAGE_TRANSFER_SRC_BIT, VMA_MEMORY_USAGE_AUTO_PREFER_HOST));
}
...
}
Note how staging buffers are created using VMA’s PREFER_HOST flag and the “main” buffer from which we read in the shader is using the PREFER_DEVICE flag.
Here’s how new data is uploaded (full implementation):
void NBuffer::uploadNewData(
VkCommandBuffer cmd,
std::size_t frameIndex,
void* newData,
std::size_t dataSize,
std::size_t offset) const
{
assert(initialized);
assert(frameIndex < framesInFlight);
assert(offset + dataSize <= gpuBufferSize && "NBuffer::uploadNewData: out of bounds write");
if (dataSize == 0) {
return;
}
// sync with previous read
... // READ BARRIER CODE HERE
auto& staging = stagingBuffers[frameIndex];
auto* mappedData = reinterpret_cast<std::uint8_t*>(staging.info.pMappedData);
memcpy((void*)&mappedData[offset], newData, dataSize);
const auto region = VkBufferCopy2{
.sType = VK_STRUCTURE_TYPE_BUFFER_COPY_2,
.srcOffset = (VkDeviceSize)offset,
.dstOffset = (VkDeviceSize)offset,
.size = dataSize,
};
const auto bufCopyInfo = VkCopyBufferInfo2{
.sType = VK_STRUCTURE_TYPE_COPY_BUFFER_INFO_2,
.srcBuffer = staging.buffer,
.dstBuffer = gpuBuffer.buffer,
.regionCount = 1,
.pRegions = ®ion,
};
vkCmdCopyBuffer2(cmd, &bufCopyInfo);
// sync with write
... // WRITE BARRIER CODE HERE
}
I’d go with the first approach for most cases (more data on GPU, but no need for manual sync) unless you need to conserve GPU memory for some reason. I’ve found no noticeable difference in performance between two approaches, but it might matter if you are uploading huge amounts of data to GPU on each frame.
Destructors, deletion queue and cleanup
Now, this might be somewhat controversial… but I didn’t find much use of the deletion queue pattern used in vkguide. I don’t really need to allocated/destroy new objects on every frame.
Using C++ destructors for Vulkan object cleanup is not very convenient either. You need to wrap everything in custom classes, add move constructors and move operator=… It adds an additional layer of complexity.
In most cases, the cleanup of Vulkan objects happens in one place - and you don’t want to accidentally destroy some in-use object mid-frame by accidentally destroying some wrapper object.
It’s also harder to manage lifetimes when you have cleanup in happening in the destructor. For example, suppose you have a case like this:
struct SomeClass {
SomeOtherClass b;
void init() {
...
}
void cleanup() {
...
}
}
If you want to cleanup SomeOtherClass resources (e.g. the instance of SomeOtherClass has a VkPipeline object) during SomeClass::cleanup, you can’t do that if the cleanup of SomeOtherClass is performed in its destructor.
Of course, you can do this:
struct SomeClass {
std::unique_ptr<SomeOtherClass> b;
void init() {
b = std::make_unique<SomeOtherClass>();
...
}
void cleanup() {
b.reset();
...
}
}
… but I don’t like how it introduces a dynamic allocation and requires you to do write more code (and it’s not that much different from calling a cleanup function manually).
Right now, I prefer to clean up stuff directly, e.g.
class SkyboxPipeline {
public:
void cleanup(VkDevice device) {
vkDestroyPipeline(device, pipeline, nullptr);
vkDestroyPipelineLayout(device, pipelineLayout, nullptr);
}
private:
VkPipelineLayout pipelineLayout;
VkPipeline pipeline;
...
}
// in GameRenderer.cpp:
void GameRenderer::cleanup(VkDevice device) {
...
skyboxPipeline.cleanup(device);
...
}
This approach is not perfect - first of all, it’s easy to forget to call cleanup function, This is not a huge problem since you get a validation error in case you forget to cleanup some Vulkan resources on shutdown:
Validation Error: [ VUID-vkDestroyDevice-device-05137 ] Object 0: handle = 0x4256c1000000005d, type = VK_OBJECT_TYPE_PIPELINE_LAYOUT; | MessageID = 0x4872eaa0 | vkCreateDevice(): OBJ ERROR : For VkDevice 0x27bd530[], VkPipelineLayout 0x4256c1000000005d[] has not been destroyed. The Vulkan spec states: All child objects created on device must have been destroyed prior to destroying device (https://vulkan.lunarg.com/doc/view/1.3.280.1/linux/1.3-extensions/vkspec.html#VUID-vkDestroyDevice-device-05137)
VMA also triggers asserts if you forget to free some buffer/image allocated with it.
I find it convenient to have all the Vulkan cleanup happening explicitly in one place. It makes it easy to track when the objects get destroyed.
Synchronization
Synchronization in Vulkan is difficult. OpenGL and WebGPU do it for you - if you read from some texture/buffer, you know that it will have the correct data and you won’t get problems with data races. With Vulkan, you need to be explicit and this is usually where things tend to get complicated.
Right now I manage most of the complexities of sync manually in one place. I separate my drawing into “passes”/pipelines (as described above) and then insert barriers between them. For example, the skinning pass writes new vertex data into GPU memory. Shadow mapping pass reads this data to render skinned meshes into the shadow map. Sync in my code looks like this:
// do skinning in compute shader
for (const auto& mesh : skinnedMeshes) {
skinningPass.doSkinning(gfxDevice, mesh);
}
{
// Sync skinning with CSM
// This is a "fat" barrier and you can potentially optimize it
// by specifying all the buffers that the next pass will read from
const auto memoryBarrier = VkMemoryBarrier2{
.sType = VK_STRUCTURE_TYPE_MEMORY_BARRIER_2,
.srcStageMask = VK_PIPELINE_STAGE_2_COMPUTE_SHADER_BIT,
.srcAccessMask = VK_ACCESS_2_SHADER_WRITE_BIT,
.dstStageMask = VK_PIPELINE_STAGE_2_VERTEX_SHADER_BIT,
.dstAccessMask = VK_ACCESS_2_MEMORY_READ_BIT,
};
const auto dependencyInfo = VkDependencyInfo{
.sType = VK_STRUCTURE_TYPE_DEPENDENCY_INFO,
.memoryBarrierCount = 1,
.pMemoryBarriers = &memoryBarrier,
};
vkCmdPipelineBarrier2(cmd, &dependencyInfo);
}
// do shadow mapping
shadowMappingPass.draw(gfxDevice, ...);
Of course, this can be automated/simplified using render graphs. This is something that I might implement in the future. Right now I’m okay with doing manual sync. vkconfig’s “synchronization” validation layer also helps greatly in finding sync errors.
The following resources were useful for understanding synchronization:
-
https://themaister.net/blog/2019/08/14/yet-another-blog-explaining-vulkan-synchronization/
-
https://github.com/KhronosGroup/Vulkan-Docs/wiki/Synchronization-Examples
More implementation notes
Drawing many sprites
With bindless textures, it’s easy to draw many sprites using one draw call without having to allocate vertex buffers at all.
First of all, you can emit vertex coordinates and UVs using gl_VertexIndex in your vertex shader like this:
void main()
{
uint b = 1 << (gl_VertexIndex % 6);
vec2 baseCoord = vec2((0x1C & b) != 0, (0xE & b) != 0);
...
}
This snippet produces this set of values:
| gl_VertexIndex | baseCoord |
|---|---|
| 0 | (0,0) |
| 1 | (0,1) |
| 2 | (1,1) |
| 3 | (1,1) |
| 4 | (1,0) |
| 5 | (0,0) |
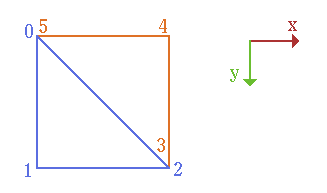
Two triangles form a quad
All the sprite draw calls are combined into SpriteDrawBuffer which looks like this in GLSL:
struct SpriteDrawCommand {
mat4 transform; // could potentially be mat2x2...
vec2 uv0; // top-left uv coord
vec2 uv1; // bottom-right uv coord
vec4 color; // color by which texture is multiplied
uint textureID; // sprite texture
uint shaderID; // explained below
vec2 padding; // padding to satisfy "scalar" requirements
};
layout (buffer_reference, scalar) readonly buffer SpriteDrawBuffer {
SpriteDrawCommand commands[];
};
On CPU/C++ side, it looks almost the same:
struct SpriteDrawCommand {
glm::mat4 transform;
glm::vec2 uv0; // top-left uv coordinate
glm::vec2 uv1; // bottom-right uv coodinate
LinearColor color; // color by which texture is multiplied by
std::uint32_t textureId; // sprite texture
std::uint32_t shaderId; // explained below
glm::vec2 padding; // padding
};
std::vector<SpriteDrawCommand> spriteDrawCommands;
I create two fixed size buffers on the GPU and then upload the contents of spriteDrawCommands (using techniques described above in the “Handling dynamic data” section).
The sprite renderer is used like this:
// record commands
renderer.beginDrawing();
{
renderer.drawSprite(sprite, pos);
renderer.drawText(font, "Hello");
renderer.drawRect(...);
}
renderer.endDrawing();
// do actual drawing later:
renderer.draw(cmd, gfxDevice, ...);
The same renderer also draws text, rectangles and lines in my engine. For example, the text is just N “draw sprite” commands for a string composed of N glyphs. Solid color rectangles and lines are achieved by using a 1x1 pixel white texture and multiplying it by SpriteCommand::color in the fragment shader.
And finally, here’s how the command to do the drawing looks like inside SpriteRenderer::draw:
vkCmdDraw(cmd, 6, spriteDrawCommands.size(), 0, 0);
// 6 vertices per instance, spriteDrawCommands.size() instances in total
The complete sprite.vert looks like this:
#version 460
#extension GL_GOOGLE_include_directive : require
#extension GL_EXT_buffer_reference : require
#include "sprite_commands.glsl"
layout (push_constant) uniform constants
{
mat4 viewProj; // 2D camera matrix
SpriteDrawBuffer drawBuffer; // where sprite draw commands are stored
} pcs;
layout (location = 0) out vec2 outUV;
layout (location = 1) out vec4 outColor;
layout (location = 2) flat out uint textureID;
layout (location = 3) flat out uint shaderID;
void main()
{
uint b = 1 << (gl_VertexIndex % 6);
vec2 baseCoord = vec2((0x1C & b) != 0, (0xE & b) != 0);
SpriteDrawCommand command = pcs.drawBuffer.commands[gl_InstanceIndex];
gl_Position = pcs.viewProj * command.transform * vec4(baseCoord, 0.f, 1.f);
outUV = (1.f - baseCoord) * command.uv0 + baseCoord * command.uv1;
outColor = command.color;
textureID = command.textureID;
shaderID = command.shaderID;
}
All the parameters of the sprite draw command are self-explanatory, but shaderID needs a bit of clarification. Currently, I use it to branch inside the fragment shader:
...
#define SPRITE_SHADER_ID 0
#define TEXT_SHADER_ID 1
void main()
{
vec4 texColor = sampleTexture2DNearest(textureID, inUV);
// text drawing is performed differently...
if (shaderID == TEXT_SHADER_ID) {
// glyph atlas uses single-channel texture
texColor = vec4(1.0, 1.0, 1.0, texColor.r);
}
if (texColor.a < 0.1) {
discard;
}
outColor = inColor * texColor;
}
This allows me to draw sprites differently depending on this ID without having to change pipelines. Of course, it can be potentially bad for the performance. This can be improved by drawing sprites with the same shader ID in batches. You’ll only need to switch pipelines when you encounter a draw command with a different shader ID.
The sprite renderer is very efficient: it can draw 10 thousand sprites in just 315 microseconds.
![]()
![]()
Compute skinning
I do skinning for skeletal animation in a compute shader. This allows me to have the same vertex format for all the meshes.
Basically, I just take the mesh’s vertices (not skinned) and joint matrices and produce a new buffer of vertices which are used in later rendering stages.
Suppose you spawn three cats with identical meshes:
All three of them can have different animations. They all have an identical “input” mesh. But the “output” vertex buffer will differ between them, which means that you need to pre-allocate a vertex buffer for each instance of the mesh.
Here’s how the skinning compute shader looks like:
#version 460
#extension GL_GOOGLE_include_directive : require
#extension GL_EXT_buffer_reference : require
#include "vertex.glsl"
struct SkinningDataType {
ivec4 jointIds;
vec4 weights;
};
layout (buffer_reference, std430) readonly buffer SkinningData {
SkinningDataType data[];
};
layout (buffer_reference, std430) readonly buffer JointMatrices {
mat4 matrices[];
};
layout (push_constant) uniform constants
{
JointMatrices jointMatrices;
uint jointMatricesStartIndex;
uint numVertices;
VertexBuffer inputBuffer;
SkinningData skinningData;
VertexBuffer outputBuffer;
} pcs;
layout (local_size_x = 256, local_size_y = 1, local_size_z = 1) in;
mat4 getJointMatrix(int jointId) {
return pcs.jointMatrices.matrices[pcs.jointMatricesStartIndex + jointId];
}
void main()
{
uint index = gl_GlobalInvocationID.x;
if (index >= pcs.numVertices) {
return;
}
SkinningDataType sd = pcs.skinningData.data[index];
mat4 skinMatrix =
sd.weights.x * getJointMatrix(sd.jointIds.x) +
sd.weights.y * getJointMatrix(sd.jointIds.y) +
sd.weights.z * getJointMatrix(sd.jointIds.z) +
sd.weights.w * getJointMatrix(sd.jointIds.w);
Vertex v = pcs.inputBuffer.vertices[index];
v.position = vec3(skinMatrix * vec4(v.position, 1.0));
pcs.outputBuffer.vertices[index] = v;
}
- I store all joint matrices in a big array and populate it every frame (and also pass the starting index in the array for each skinned mesh,
jointMatricesStartIndex). - Skinning data is not stored inside each mesh vertex, a separate buffer of
num_verticeselements is used.
After the skinning is performed, all the later rendering stages use this set of vertices Thee rendering process for static and skinned meshes becomes identical, thanks to that.
Anton’s OpenGL 4 Tutorials book has the best skinning implementation guide I’ve ever read. Game Engine Architecture by Jason Gregory has nice explanations about skinning/skeletal animation math as well.
Game / renderer separation
I have a game/renderer separation which uses a simple concept of “draw commands”. In the game logic, I use entt, but the renderer doesn’t know anything about entities or “game objects”. It only knows about the lights, some scene parameters (like fog, which skybox texture to use etc) and meshes it needs to draw.
The renderer’s API looks like this in action:
void Game::generateDrawList()
{
renderer.beginDrawing();
// Add lights
const auto lights = ...; // get list of all active lights
for (const auto&& [e, tc, lc] : lights.each()) {
renderer.addLight(lc.light, tc.transform);
}
// Render static meshes
const auto staticMeshes = ...; // list of entities with static meshes
for (const auto&& [e, tc, mc] : staticMeshes.each()) {
// Each "mesh" can have multiple submeshes similar to how
// glTF separates each "mesh" into "primitives".
for (std::size_t i = 0; i < mc.meshes.size(); ++i) {
renderer.drawMesh(mc.meshes[i], tc.worldTransform, mc.castShadow);
}
}
// Render meshes with skeletal animation
const auto skinnedMeshes = ...; // list of entities with skeletal animations
for (const auto&& [e, tc, mc, sc] : skinnedMeshes.each()) {
renderer.drawSkinnedMesh(
mc.meshes, sc.skinnedMeshes, tc.worldTransform,
sc.skeletonAnimator.getJointMatrices());
}
renderer.endDrawing();
}
When you call drawMesh or drawSkinnedMesh, the renderer creates a mesh draw command and puts it in std::vector<MeshDrawCommand> which are then iterated through during the drawing process. The MeshDrawCommand looks like this:
struct SkinnedMesh {
GPUBuffer skinnedVertexBuffer;
};
struct MeshDrawCommand {
MeshId meshId;
glm::mat4 transformMatrix;
math::Sphere worldBoundingSphere;
const SkinnedMesh* skinnedMesh{nullptr};
std::uint32_t jointMatricesStartIndex;
bool castShadow{true};
};
meshIdis used for looking up static meshes inMeshCache- it’s a simplestd::vectorof references to vertex buffers on GPU.- If the mesh has a skeleton,
jointMatricesStartIndexis used during compute skinning andskinnedMesh->skinnedVertexBufferis used for all the rendering afterwards (instead ofmeshId) worldBoundingSphereis used for frustum culling.
This separation is nice because the renderer is clearly separated from the game logic. You can also do something more clever as described here if sorting draw commands becomes a bottleneck.
Scene loading and entity prefabs
I use Blender as a level editor and export it as glTF. It’s easy to place objects, colliders and lights there. Here’s how it looks like:

Writing your own level editor would probably take months (years!), so using Blender instead saved me quite a lot of time.
It’s important to mention how I use node names for spawning some objects. For example, you can see an object named Interact.Sphere.Diary selected in the screenshot above. The part before the first dot is the prefab name (in this case “Interact”). The “Sphere” part is used by the physics system to create a sphere physics body for the object (“Capsule” and “Box” can also be used, otherwise the physics shape is created using mesh vertices).
Some models are pretty complex and I don’t want to place them directly into the level glTF file as it’ll greatly increase each level’s size. I just place an “Empty->Arrows” object and name it something like “Cat.NearStore”. This will spawn “Cat” prefab and attach “NearStore” tag to it for runtime identification.
Prefabs are written in JSON and look like this:
{
"scene": {
"scene": "assets/models/cato.gltf"
},
"movement": {
"maxSpeed": [4, 4, 4]
},
"physics": {
"type": "dynamic",
"bodyType": "virtual_character",
"bodyParams": {
...
}
}
}
During the level loading process, if the node doesn’t have a corresponding prefab, it’s loaded as-is and its mesh data is taken from the glTF file itself (this is mostly used for static geometry). If the node has a corresponding prefab loaded, it’s created instead. Its mesh data is loaded from the external glTF file - only transform is copied from the original glTF node (the one in the level glTF file).
Once glTFX is released and the support for it is added to Blender, things might be even easier to handle as you’ll be able to reference external glTF files with it.
MSAA
Using forward rendering allowed me to easily implement MSAA. Here’s a comparison of how the game looks without AA and with MSAA on:
No AA
MSAA x8

MSAA is explained well here: https://vulkan-tutorial.com/Multisampling
Here’s another good article about MSAA: https://therealmjp.github.io/posts/msaa-overview/ and potential problems you can have with it (especially with HDR and tone-mapping).
UI
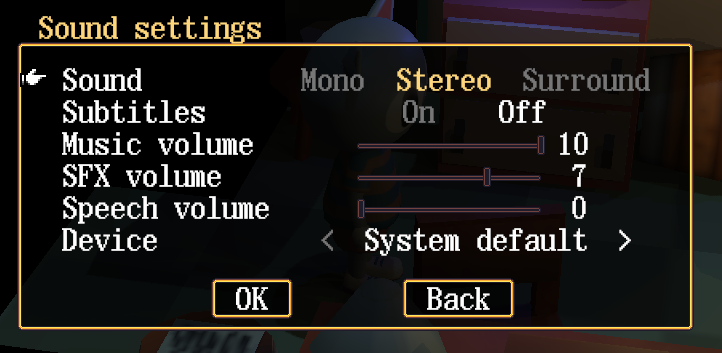
My UI system was inspired by Roblox’s UI API: https://create.roblox.com/docs/ui
Basically, the UI can calculate its own layout without me having to hard code each individual element’s size and position. Basically it relies on the following concepts:
- Origin is an anchor around which the UI element is positioned. If origin is
(0, 0), setting UI element’s position to be(x,y)will make its upper-left pixel have (x,y) pixel coordinate. If the origin is(1, 1), then the element’s bottom-right corner will be positioned at(x, y). If the origin is (0.5, 1) then it will be positioned using bottom-center point as the reference.
- Relative size makes the children’s be proportional to parent’s size. If (1,1) then the child element will have the same size as the parent element. If it’s (0.5, 0.5) then it’ll have half the size of the parent. If the parent uses children’s size as a guide, then if a child has (0.5, 0.25) relative size, the parent’s width will be 2x larger and the height will be 4x larger.
- Relative position uses parent’s size as a guide for positioning. It’s useful for centering elements, for example if you have an element with (0.5, 0.5) origin and (0.5, 0.5) relative position, it’ll be centered inside its parent element.
- You can also set pixel offsets for both position and size separately (they’re called
offsetPositionandoffsetSizein my codebase). - You can also set a fixed size for the elements if you don’t want them to ever be resized.
- The label/image element size is determined using its content.
Here are some examples of how it can be used to position child elements:

a) The child (yellow) has relative size (0.5, 1), relative position of (0.5, 0.5) and origin (0.5, 0.5) (alternatively, the relative position can be (0.5, 0.0) and origin at (0.5, 0.0) in this case). Its parent (green) will be two times wider, but will have the same height. The child element will be centered inside the parent.
b) The child (yellow) has origin (1, 1), fixed size (w,h) and absolute offset of (x,y) - this way, the item can be positioned relative to the bottom-right corner of its parent (green)
Let’s see how sizes and positions of UI elements are calculated (implementation in EDBR).
First, sizes of all elements are calculated recursively. Then positions are computed based on the previously computed sizes and specified offset positions. Afterwards all elements are drawn recursively - parent element first, then its children etc.
When calculating the size, most elements either have a “fixed” size (which you can set manually, e.g. you can set some button to always be 60x60 pixels) or their size is computed based on their content. For example, for label elements, their size is computed using the text’s bounding box. For image elements, their size equals the image size and so on.
If an element has an “Auto-size” property, it needs to specify which child will be used to calculate its size. For example, the menu nine-slice can have several text labels inside the “vertical layout” element - the bounding boxes will be calculated first, then their sizes will be summed up - then, the parent’s size is calculated.
Let’s take a look at a simple menu with bounding boxes displayed:
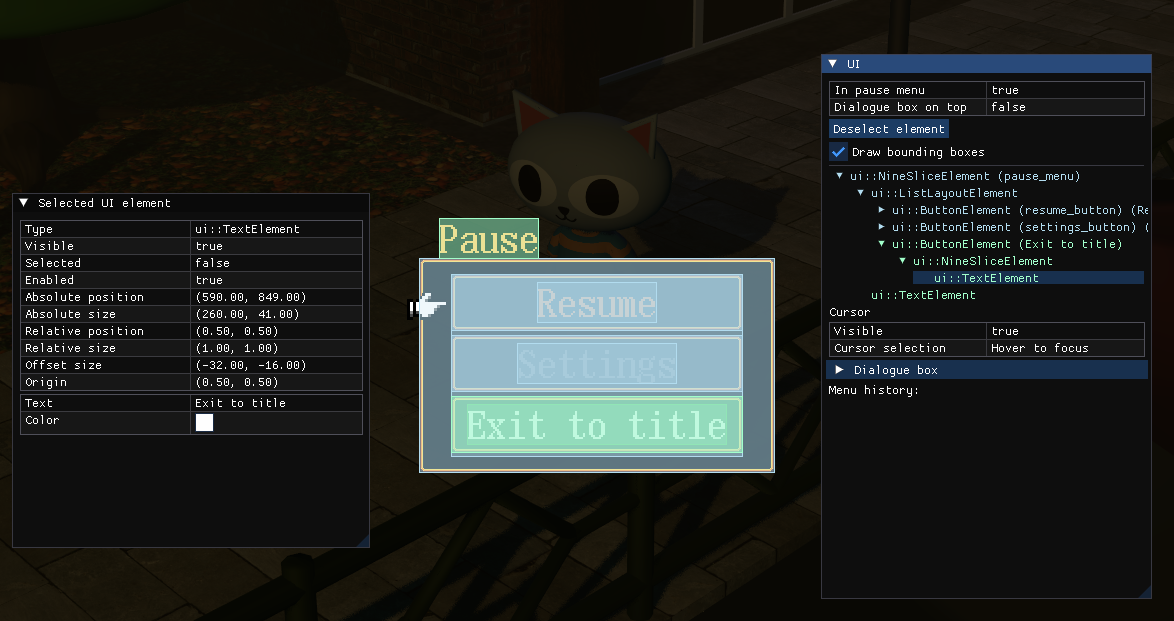
Here, root NineSliceElement is marked as “Auto-size”. To compute its size, it first computes the size of its child (ListLayoutElement). This recursively computes the sizes of each button, sums them up and adds some padding (ListLayoutElement also makes the width of each button the same based on the maximum width in the list).
Dear ImGui and sRGB issues
I love Dear ImGui. I used it to implement many useful dev and debug tools (open the image in a new tab to see them better):
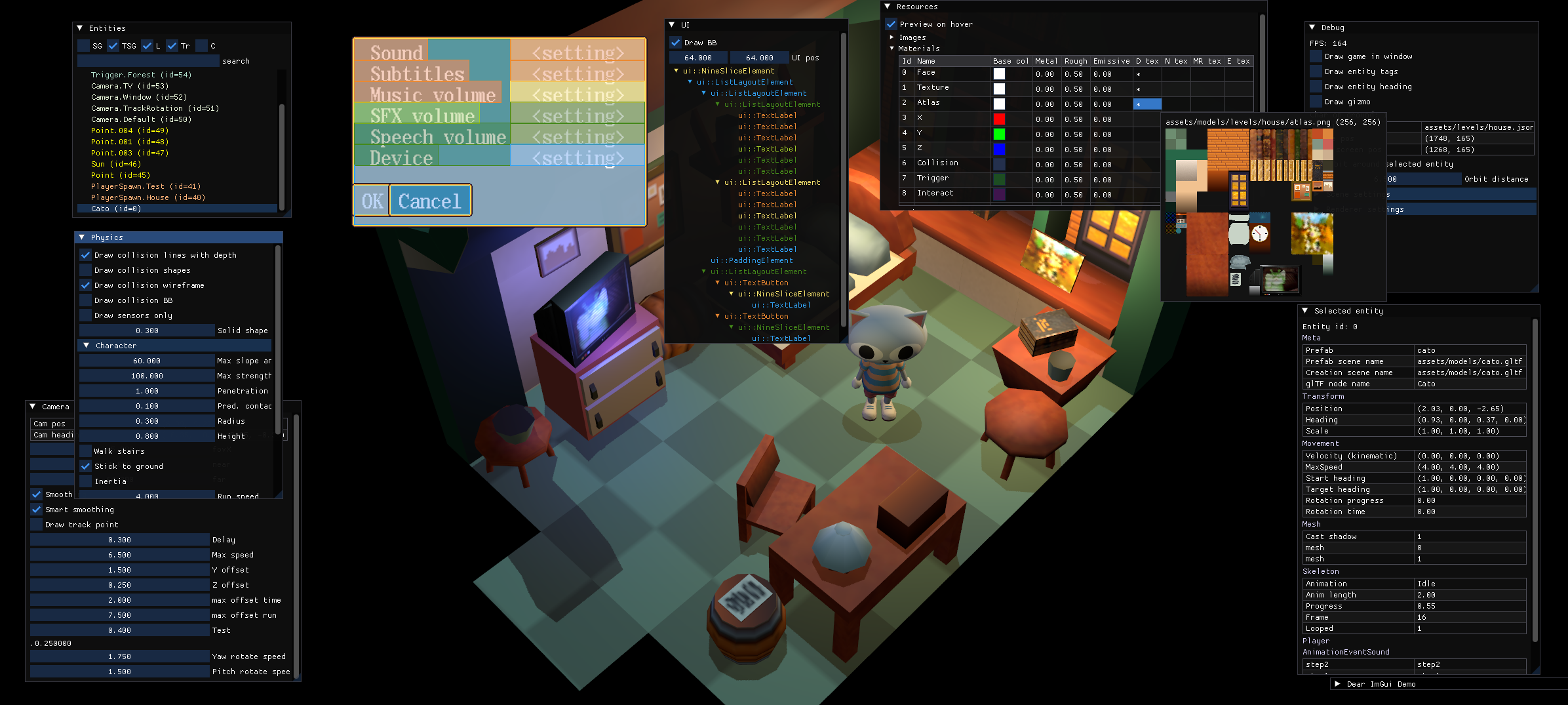
It has some problems with sRGB, though. I won’t explain it in detail, but basically if you use sRGB framebuffer, Dear ImGui will look wrong in many ways, see the comparison:
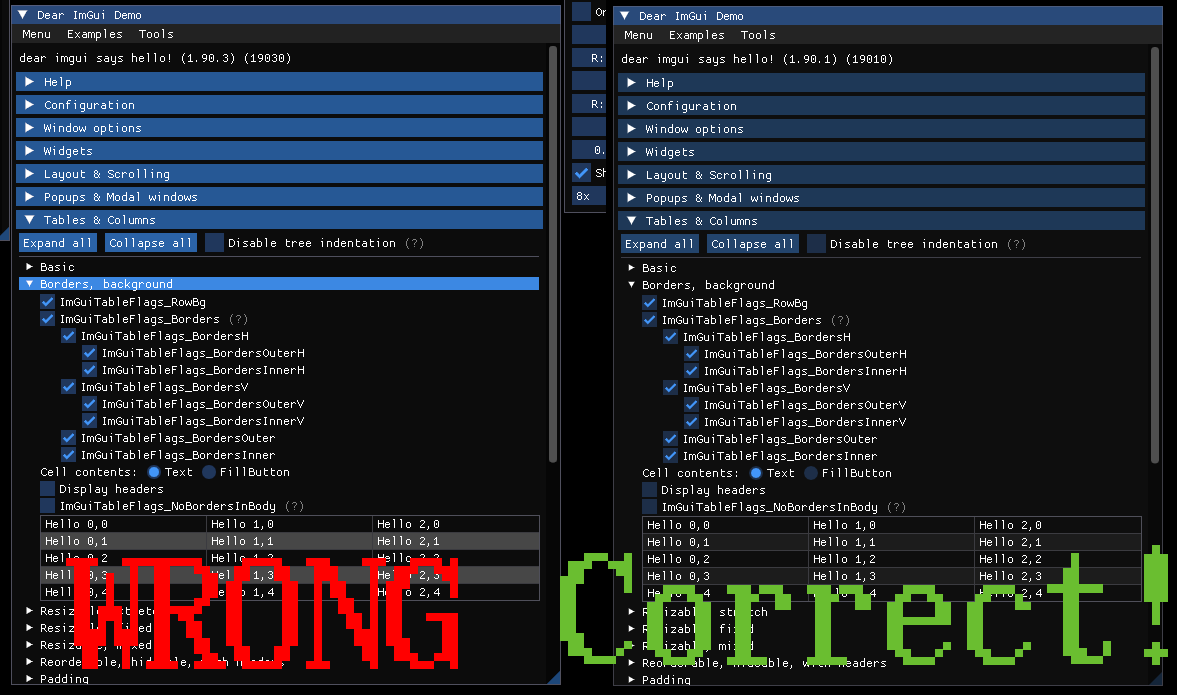
Left - naive sRGB fix for Dear ImGui, right - proper fix
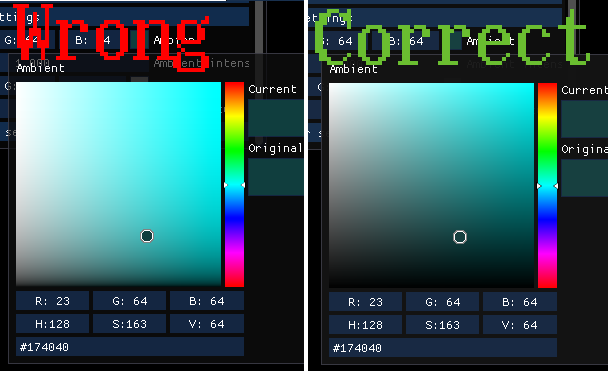
Left - naive sRGB fix for Dear ImGui, right - proper fix
Sometimes you can see people doing hacks by doing pow(col, vec4(2.2)) with Dear ImGui’s colors but it still doesn’t work properly with alpha and produces incorrect color pickers.
I ended up writing my own Dear ImGui backend and implementing DilligentEngine’s workaround which is explained in detail here and here.
Writing it wasn’t as hard as I expected. I only need to write the rendering part, while “logic/OS interaction” part (input event processing, clipboard etc.) is still handled by default Dear ImGui SDL backend in my case.
There are some additional benefits of having my own backend:
- It supports bindless texture ids, so I can draw images by simply calling
ImGui::Image(bindlessTextureId, ...). Dear ImGui’s Vulkan backend requires you to “register” textures by callingImGui_ImplVulkan_AddTexturefor each texture before you can callImGui::Image. - It can properly draw linear and non-linear images by passing their format into backend (so that sRGB images are not gamma corrected twice when they’re displayed)
- Initializing and dealing with it is easier as it does Vulkan things in the same way as the rest of my engine.
Other stuff
There are many parts of the engine not covered there because they’re not related to Vulkan. I still feel like it’s good to mention them briefly for the sake of completion.
- I use Jolt Physics for physics.
Integrating it into the engine was pretty easy. Right now I mostly use it for collision resolution and basic character movement.
The samples are fantastic. The docs are very good too.
I especially want to point out how incredible JPH::CharacterVirtual is. It handles basic character movement so well. I remember spending days trying to get proper slope movement in Bullet to work. With Jolt, it just worked “out of the box”.
Here’s how it basically works (explaining how it works properly would probably require me to write quite a big article):
- You add your shapes to Jolt’s world.
- You run the simulation.
- You get new positions of your physics objects and use these positions to render objects in their current positions.

I implemented Jolt physics shape debug renderer using im3d
- I use entt for the entity-component-system part.
It has worked great for me so far. Previously I had my own ECS implementation, but decided to experiment with a 3rd party ECS library to have less code to maintain.
- I use openal-soft, libogg and libvorbis for audio.
The audio system is mostly based on these articles: https://indiegamedev.net/2020/02/15/the-complete-guide-to-openal-with-c-part-1-playing-a-sound/
- I use Tracy for profiling.
Integrating it was very easy (read the PDF doc, it’s fantastic!) and it helped me avoid tons of bike-shedding by seeing how little time something, which I thought was “inefficient”, really took.

What I gained from switching to Vulkan
There are many nice things I got after switching to Vulkan:
- No more global state
This makes abstractions a lot easier. With OpenGL abstractions/engines, you frequently see “shader.bind()” calls, state trackers, magic RAII, which automatically binds/unbinds objects and so on. There’s no need for that in Vulkan - it’s easy to write functions which take some objects as an input and produce some output - stateless, more explicit and easier to reason about.
- API is more pleasant to work with overall - I didn’t like “binding” things and the whole “global state machine” of OpenGL.
- You need to write less abstractions overall.
With OpenGL, you need to write a lot of abstractions to make it all less error-prone… Vulkan’s API requires a lot less of this, in my experience. And usually the abstractions that you write map closer to Vulkan’s “raw” functions, compared to OpenGL abstractions which hide manipulation of global state and usually call several functions (and might do some stateful things for optimization).
- Better validation errors
Validation errors are very good in Vulkan. While OpenGL has glDebugMessageCallback, it doesn’t catch that many issues and you’re left wondering why your texture looks weird, why your lighting is broken and so on. Vulkan has more extensive validation which makes the debugging process much better.
- Debugging in RenderDoc
I can now debug shaders in RenderDoc. It looks like this:

With OpenGL I had to output the values to some texture and color-pick them… which took a lot of time. But now I can debug vertex and fragment shaders easily.
- More consistent experience across different GPUs and OSes.
With OpenGL, drivers on different GPUs and OSes worked differently from each other which made some bugs pop up only on certain hardware configurations. It made the process of debugging them hard. I still experienced some slight differences between different GPUs in Vulkan, but it’s much less prevalent compared to OpenGL.
- Ability to use better shading languages in the future
GLSL is a fine shading language, but there are some new shading languages which promise to be more feature-complete, convenient and readable, for example:
I might explore them in the future and see if they offer me something that GLSL lacks.
- More control over every aspect of the graphics pipeline.
- Second system effect, but good
My first OpenGL engine was written during the process of learning graphics programming from scratch. Many abstractions were not that good and rewriting them with some graphics programming knowledge (and some help from vkguide) helped me implement a much cleaner system.
- Street cred
And finally, it makes me proud to be able to say “I have a custom engine written in Vulkan and it works”. Sometimes people start thinking about you as a coding wizard and it makes me happy and proud of my work. :)
Future work
There are many things that I plan to do in the future, here’s a list of some of them:
- Sign-distance field font support (good article about implementing them)
- Loading many images and generating mipmaps in parallel (or use image formats which already have mipmaps stored inside of them)
- Bloom.
- Volumetric fog.
- Animation blending.
- Render graphs.
- Ambient occlusion.
- Finishing the game? (hopefully…)
Overall, I’m quite satisfied with what I managed to accomplish. Learning Vulkan was quite difficult, but it wasn’t as hard as I imagined. It taught me a lot about graphics programming and modern APIs and now I have a strong foundation to build my games with.